How does Google's "search for similar images" feature work?
I need to create a manager for a very extensive image bank, where in this manager in addition to the search for title and description, there should be a feature that searches for visually similar images.
For this case I was thinking of "splitting" an image into blocks and saving the color predominance information of each block, but I believe that in this way it would only be possible to find images of similar colors.
How does the Google to find similar images?
1 answers
I can't tell you how exactly Google's specific algorithm works, but I can offer some help on what the basic principle of image search by content is like.
This area is commonly called CBIR (Content-Based Image Retrieval, or image recovery based on content in Portuguese), as it involves the search for images from its content. It is an area of great interest but difficult to solve because the images are difficult computer interpretation (that is why it is widely used captchas to prevent automated access to web pages).
There are some traditional approaches to solving this problem.
1. Annotation-based search
The idea of annotating images with descriptive labels of their content is the simplest. You just create a database containing the images and texts (labels) that describe it. Imagine, for example, the image of a puppy of dog. The database can contain for them the words "puppy", "dog", "labrador" (if applicable), and so on. The search would then be carried out based on the annotations, with the images being returned those whose annotations best match the search term. I suppose this is the main algorithm used by Google, when you search for images using text expressions.
The great difficulty of this method is that it is laborious and tedious to make notes image manuals. Therefore, there are partially automated solutions. Google, most likely, uses human reinforcement from the searches carried out. You type any text ("puppy", in the previous example - a word that is not yet listed as an annotation) and it displays more and less "relevant" images based on the links between them. If you click on a less relevant image (which does not yet have such a label), this can be considered an indication that you, like human, validated that this label is also applicable. If more people do the same, then Google can automatically add such a label to the image, and increase its relevance as these specific searches occur.
Another idea is to use human-maintained tag sources, such as Flickr and/or Pinterest. Although it is an understanding task, those who like photography feel pleasure in doing it in this context. In addition, there is community work in the labeling, which facilitates the existence of new labels.
There is also the idea of using games to automate lettering. The idea is quite simple, but very clever: with a guessing game, two people (who do not necessarily know each other) play on the Internet. The game simply presents a photo (of a labrador puppy, for example) to one of the players, and the other player (who does not see the photo) needs to guess based on questions that can only be answered with yes or not by the Playmate. The questions (for example, " is a animal ?) that are answered as Yes , become labels automatically, and the relevance stems from the number of occurrences between different matches. I unfortunately lost the reference of this game, but there are numerous others like the ESP-Game (which is very similar) and the Name-it-Game (which makes the annotation by Regions).
2. Similarity based search
One of the problems of previous approach is that even if the images are very well labeled there can still be important semantic difficulties. A classic example is the search for the term "pig". This term can return images that are labeled correctly, but that are very distinct and do not necessarily represent what the user wanted at the time of the search. Here is a classic example (here in Brazil, at least):
- an image of Pig Island (a coastal island Paulista)
- a picture of a stick (collective) of pigs (the animal)
- an image of related to the Palmeiras football team (São Paulo team whose nickname is "Porco")
{kind=link}
{kind=link}
{kind=link}
The idea of this second approach is to improve the search by avoiding the use of text, but by making the search for images that are similar to a reference image provided by the user (feature that Google Images also has available).
The great difficulty this approach is precisely to define similarity. There are three traditional ways (and I suppose Google uses a mixture of the first two): similarity by color, similarity by texture, and location of landmarks.
In color similarity the algorithm can perform a numerical measurement of the colors in the reference image, and then search in a database in which such a measurement is already pre-calculated (after all, doing this calculation with each search is computationally unfeasible). There are numerous algorithms, but the simplest is the following (the original source of this suggestion is this answer in SOEN):
- scale the images to a small size (64x64, for example, so that the details are less important in the comparison).
- scale the colors to the same range (so that both images have the darkest color as black and the lightest color as white).
- rotate and invert the images so that the most light and darker stay in standardized locations (lighter in the upper left corner and darker in the lower right corner, for example, so that both are in the same orientation).
- then take the difference between each pixel and calculate the average difference. When closer to zero, the more similar the images will be.
It is also common to combine color comparison with the locations and/or format in which they occur. How does the average difference from the previous algorithm provide a single value for the whole image, the comparison will result in something like you yourself said in the question: compare by the general predominance of color. In this case, an alternative is - rather than having a single average difference value - to have a quadtree with average values for different regions (and sub-regions) of the image. Thus, the comparison by similarity will still be by predominance of colors, but in specific regions in order to generate potentially more accurate.
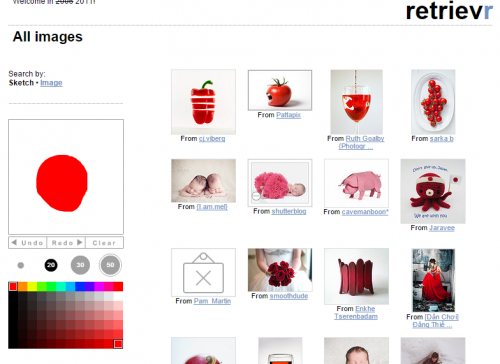
In the not too distant past there was a commercial product from IBM called QBIC, which came to be used in museums to facilitate the search for paintings: you only had to draw more or less the picture you wanted (light blue sky, dark blue sea, yellow sand, for example) and he found similar images. Unfortunately I did not find museums that still use this technology, but there is this example of Finder called Retrievr that does exactly the same, searching images similar to what you draw on Flickr. :)
There is also another algorithm widely used to define similarity: the comparison of the normalized color histogram. A histogram is nothing more than a frequency distribution, that is, the number of occurrences of something (each pixel value, for example) in a context (in the image, for example). The color histogram does not separate occurrences by pixel value, but by each color in a sequence of colors (which you define yourself, do not have to be only RGB). Similar images have this very similar distribution, and the advantage is that when the histogram is normalized (that is, transformed into a percentage of each color, not to matter the total number of pixels) this makes the comparison independent of rotation and scale in the images. See this other answer from Soen for more details on the implementation (there is a reference to slides with help to get histograms in OpenCV, for example).
Thus, you can implement this algorithm as follows:
- calculate the color histogram for both images (in each image, count the pixels and accumulate that count into" categories " of colors that you set - in the Wikipedia example pixels are counted for each RGB combination, but with the pixel values staggered to [0 to 3] to make it easier - that is, to decrease the size of the table). Of course, in the case of images in the database these values can (should!) be pre-calculated.
- Normalize the values in each category by dividing the value by the total number of pixels. This will result in the value in percentage format, easier to compare.
- Compare the histograms of the two images by measuring, for example, the average error rate. For each category, take the difference between the values in the two images. Then take the average difference between all categories. The more similar to image, the closer to zero will be this difference.
In texture similarity we try to define the (mathematical) pattern of the image texture. You can imagine something like the sequence of " Light-Dark-Light-Dark -..."that occurs in an image of a tiled floor, for example. Something very used in this case are the Gabor filters. These filters are very sensitive to border variations in the image (borders are important details) in different orientations (vertical, horizontal, diagonal, etc.). These filters are considered to be very close to how the human eye responds to the same visual stimuli, but regardless the fact is that they are very useful for describing the texture of an image.
In Patrick Fuller's blog there is a fantastic tutorial) of 6 parts that will explain you very easily (and with examples in C++) the principle of image processing until you reach the Filter Gabor. Worth reading!
Thus, it is possible to extract this pattern from an image and then use it in searches. It is also very common to use machine learning algorithms to learn the pattern of a set of sample images and use them to classify new images (as being from something "already known"). This Python example demonstrates just that, using the Scikit-Learn Library. He learns the pattern of brick, grass and wall, and uses it in the function match to compare the texture characteristics ( features ) of two images (using the least squares to define the "error" - that the closer to zero, the more similar the images are).

Finally, there is also the possibility to compare the images directly in terms of the detail of their content, in order to try to find images that are similar in terms of these occurrence. The idea is to first find in the images the most relevant edge characteristics (features), and then check if the same characteristics occur in the two images (the reference and the being compared in the search).
This approach is most often used to overlay partial images (to automatically join them and create a 360º panorama, for example), but could also be used to compare content in a search. There are ready-made examples in OpenCV, both to identify the most relevant characteristics , and to make their location between images (matching):
