How does GROUP BY work in MySQL?
Hello.
Question on sql clause GROUP BY.
-
Consider grouping by ONE column. Example:
SELECT DEPARTMENT_ID, SUM(SALARY) FROM Employees GROUP BY DEPARTMENT_ID;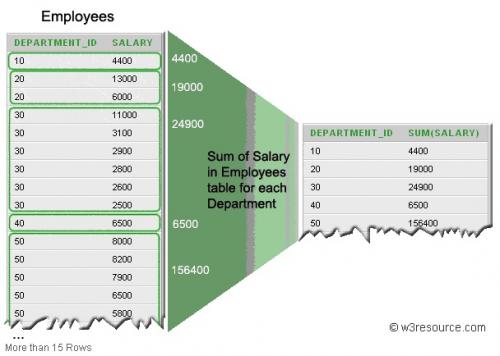
That is, in the
DEPARTMENT_IDcolumn, is searched for a unique (similar toDISTINCT) department value, for example, 30, then all rows where department 30 is mentioned in this table, from these rows the values from columnSALARYare taken and are summed up (SUM). Then another buyer is searched for and everything repeats. As a result, I get how much money each department received in general.I don't understand the point: I have 6 rows that have a column
DEPARTMENT_IDwith a value of 30. Which of the rows will go to the table -SELECTand why? That is, in the tableEmployeesthere were six rows withDEPARTMENT_ID30, and in the table -SELECTsuch a row is only one. How does this grouping work in general? Consider grouping by to two columns. I don't understand her at all. I didn't even find a normal picture, from which it would be clear. I looked through a bunch of articles and books on this subject, but I didn't understand anything.
2 answers
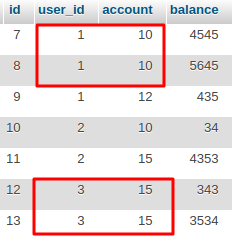
I will add an example of queries and output of GROUP BY in two fields. You can look at the table in which, for example, which user (user_id) deposited money, to which account (account) and how much (balance) is saved. For example, you need to find out how much each user has deposited to each of their accounts.
SELECT MIN(user_id), MIN(account), SUM(balance) FROM `t1` GROUP BY user_id, account;
GROUP BY works on two fields as well as on one, first sorts, and then looks if both values in the row are the same as in the previous row, then groups these lines. If at least one value is not the same as in the previous row, then there will be no grouping. For 3 or more fields, GROUP BY works the same way.
Result:
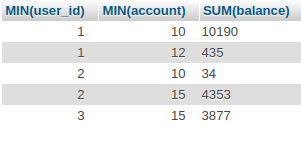
None of the original rows will be included in the selection after group by. At the output, the aggregate is the sum of the data in the desired section. For columns to which you have not explicitly applied any group functions (such as sum()), the "first-come-first-served"function will be applied. And only in MySQL and only when the ONLY_FULL_GROUP_BY option is disabled. In other DBMSs, a query in which at least one column that is not the section specified in group by "forgot" to apply the group function will return an error.
How it works group by can be calculated in excel. Write the data on the sheet, sort it by the fields that should be in group by. Reading sorted data in a row in any case, when the value in the next row in the columns specified in group by differs from the values in the previous one-insert a new row, copy the values of the columns group by, and put formulas like СУММ() in the remaining cells of the group under which the total is summed up. The result group by is exactly these inserted totals. The DBMS works approximately on the same algorithm-first sorts, then sums up consecutive identical records.
I will add about MySQL - it is still too free to treat this. Always try to explicitly apply group functions to all columns, so that you can understand what exactly will be in them, because the 'first thing' is not standardized and can change from version to version, depending on the physical location of the records on the disk and the query execution plan.