How does the train test split method work in Scikit Learn?
I am learning machine learning and in most examples the method train_test_split() is used and there is not a very precise explanation about it (at least not in the articles I have already read).
I know your function is to split the dataset, but I have some doubts:
- Why do data need to be split?
- What is the purpose of the return variables
trainandtest? - is used only for productivity or there is an increase on the accuracy rate of training?
3 answers
Well, to understand this question, it is illustrative to start by presenting the conceptual difference between supervised and unsupervised Machine Learning models. Starting with the latter, unsupervised models are models that seek to make an estimate in a context that the response variable is not known. The classic case are implementations of core component models. In these models, you can create components based on correlations of variables in the bank, although most often the practical representation or concrete meaning of these components is unknown.
On the other hand, in supervised models, the dependent variable (or output, explained variable, response variable) is known. An example would be a model that tries to predict the participation of women in the labor market based on variables such as age, education, number of children, among others. The dependent variable in this case is a dummy which assumes value 1 if the woman is in the labor market and 0 if she is not. When you adjust the model to make this prediction it is important to know the predictive ability of your model, in addition to the data on which it was trained. For this reason, it is common to separate your database into workout and Test . The data in the training base, are used when training the model, while the data in the test base, test the performance of the model outside the sample (with new data).
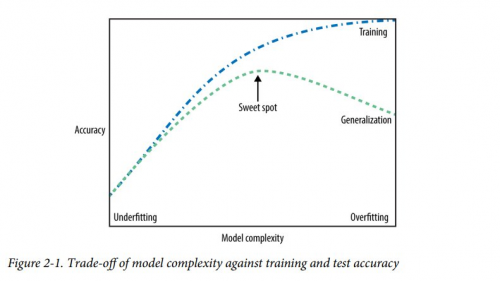
It is important to note that there will always be a difference in model performance in the different bases (training and test). In fact, this difference is always in favor of the training base (think, the model already "knows" those data). From this difference it is possible to formulate another relevant distinction in Machine Learning, which is the difference between underfitting and overfitting. As the figure below shows, taken from Andreas Müller's book, we say that the model is underfitting when its performance is poor both in the training base and in the test base. When we increase the complexity of the model, its performance improves on both bases. However, a very complex model is very "fit for the training base", that is, it hits the training base a lot, but has little generalization power. This is what we call overfitting. Note that, from the data scientist's perspective, the challenge it consists in maximizing accuracy, without losing the ability to generalize.
In short, the separation of the base into training base and test base is fundamental to know:
1) the accuracy of the model and
2) how much can we improve it without losing generalization ability
That's how I understand it, it would be nice to see other views
Why does data need to be split?
An ML algorithm is expected to learn from the training set, but then how do we know if the model looked good? Whether it works with new data? How do we compare with other models?
The answer is simple, we see the score (accuracy) in the test set. This score tells us how well the model will behave with new data.
What is the purpose of the return variables train and test?
The purpose of these variables is to use the dataset train to train the model and, with a dataset never seen before, the test, to see how the model handles new data.
Is it used only for productivity or is there an increase in the accuracy rate of training?
By performing several trainings with different data sets (treino and test), we can find the best hyper parameters for the model that maximize accuracy average of the various test sets.
Then dividing into training and testing improves the final model, which should be trained with the entire dataset and with the hyper parameter already established.
Being very didactic and straightforward, the training set is the basis that you provide your AI for it to learn. So this set she already knows. After training an AI it is common to need to analyze how good it is, for this it is necessary to provide a set of data that it has never been trained and see how well it does in the classification of the data. If the same training set is used for testing, AI tends to have better results than it actually would when exposed to other data same kind.
The process is analogous to the teacher who teaches students and then to test them applies a test with different questions. If it applies the same questions that students have already asked or seen, students tend to get better grades .