How to normalize data? Any sklearn libraries?
I need to normalize data I have so that it is between -1 and 1.
I used StandardScaler, but the range got bigger.
What other sklearn library could you use? There are several in sklearn, but I could not, it should make life easier, but I believe I'm not knowing how to use.
What I tried was:
df = pd.read_fwf('traco_treino.txt', header=None)
plt.plot(df)
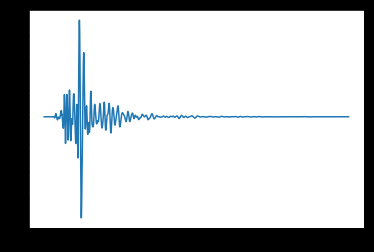
Data in the range -4 and 4
After attempting normalization:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(df)
dftrans = scaler.transform(df)
plt.plot(dftrans)
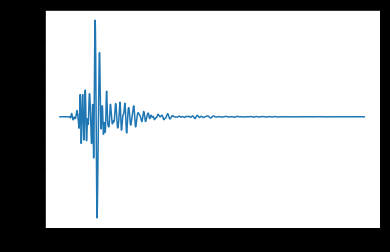
The die is between -10 and 10.
3
1 answers
O StandardScaler standardizes the data to a unit of variance ( var =1) and not to a range, so the results differ from expected.
To standardize the data in the range (-1, 1), use the MaxAbsScaler:
import numpy as np
from sklearn.preprocessing import MaxAbsScaler
# Define os dados
dados = np.array([[0, 0], [300, -4], [400, 3.8], [1000, 0.5], [3000, 0]], dtype=np.float64)
dados
=> array([[ 0.00000000e+00, 0.00000000e+00],
[ 3.00000000e+02, -4.00000000e+00],
[ 4.00000000e+02, 3.80000000e+00],
[ 1.00000000e+03, 5.00000000e-01],
[ 3.00000000e+03, 0.00000000e+00]])
# Instancia o MaxAbsScaler
p=MaxAbsScaler()
# Analisa os dados e prepara o padronizador
p.fit(dados)
=> MaxAbsScaler(copy=True)
# Transforma os dados
print(p.transform(dados))
=> [[ 0. 0. ]
[ 0.1 -1. ]
[ 0.13333333 0.95 ]
[ 0.33333333 0.125 ]
[ 1. 0. ]]
More information in documentation or Wikipedia: feature scaling
5
Author: Gomiero, 2018-05-16 00:10:41