Python average relative error of regression approximation
I'm new to python and don't quite understand how I can calculate the average relative approximation error using the formula 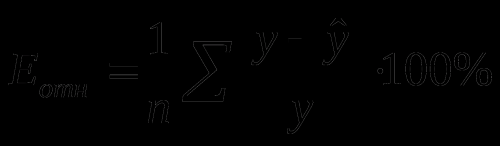
import pandas as pd
import math
from sklearn import svm
from sklearn import preprocessing
df = pd.read_csv('file1.csv',";",header=None)
X_train = df.drop([16,17],axis=1)
Y_train = df[16]
test_data = pd.read_csv('file2.csv',";",header=None)
X_test = test_data.drop([16,17],axis=1)
Y_test = test_data[16]
normalized_X_train = preprocessing.normalize(X_train)
normalized_X_test = preprocessing.normalize(X_test)
xgb_model = svm.SVR(kernel='linear', C=1000.0)
cl = xgb_model.fit(normalized_X_train,Y_train)
predictions = cl.predict(normalized_X_test)
Is there some ready-made function for getting this error, or is it just a loop? If it is a loop, do I need to normalize Y_test-real values?
0
1 answers
You can do this:
from sklearn.metrics import mean_absolute_error
mape = mean_absolute_error(y_test, y_predicted) / y_test.abs().sum()
If you need percentages, then mape should be multiplied by 100.
PS It is also worth mentioning that this metric is rarely used in practice. It can cause division by zero.
1
Author: MaxU, 2019-10-23 07:25:08