How to model a tree data structure using a relational database?
How to properly and efficiently define naturally tree-organized data in relational databases, considering the physical implications of this? That is, organize in a way that minimizes accesses made on any node.
Assume that RDBMS has no special features to handle this except the ANSI SQL DDL or features available in all major relational database systems. Eventually an optimization specific optional may be useful, but not mandatory.
If there is a way ( query ) more suitable for accessing (scanning/traversing) data structured in this way, an example would help.
3 answers
Well, it is always preferable to use an SGDB that treats data in tree in a natural way, even better when it is specially designed for this purpose, such as Neo4j.
But there are some ways to work in relational DBMS, I will enumerate 4 of them:
1. Adjacent List
Most Commonly Used solution, each entry (record) knows only its top node, see an example of commonly used structure used:
Example: comments on a blog
In this example, there is a table that stores comments from a blog, there are the main comments, which have no top nodes (they are the "root"), and there are the comments that are responses to another comment, and so susceptibly, in a DBMS table, we would have the following situation:
Table: comentarios
id parent_id usuario_id comentario
----------------------------------------------------------------
1 NULL 33 Gostei do seu...
2 1 34 seu comentario foi exc...
3 1 99 Gostei Também...
4 3 34 Que bom que gostou...
5 NULL 80 Que Post Bacana ...
Rendering, we would have something like:
Usuario 33 Comentou: Gostei do seu ...
Usuário 34 Comentou: Seu comentario foi exc...
Usuario 99 Comentou: Gostei Também...
Usuário 34 Comentou: Que bom que gostou...
Usuario 80 Comentou: Que Post Bacana ...
The comments have the data structure table, although they are nested in this way, it is necessary to recursively traverse all data from a given ID.
Positive points : easy to implement
negative points : difficult to handle in deeparvores, works well when there are few levels
2. Enumerated Path
Basically the same structure as the example above, but the table contains the path from the root node to itself, see the example:
Table comentarios
id path_to_comment usuario_id comentario
----------------------------------------------------------------
1 / 33 Gostei do seu...
2 /1/2 34 seu comentario foi exc...
3 /1/3 99 Gostei Também...
4 /1/3/4 34 Que bom que gostou...
5 / 80 Que Post Bacana ...
In this way we could take the Comets below the comment of ID 3 by doing something like
SELECT * from comentarios WHERE path_to_comment LIKE '/1/3/%';
Positive points : easy to implement, query faster and more efficient than
Lista Adjacente
negative points : it is relatively difficult to redo the path when we relocate an element
3. Nested Sets
Is a slightly more complex method, I will give an overview, for a complete answer would greatly prolong an answer that is an overview on the methods, so let's go:
Consist of storing with each node, two numbers (one to the left and one to the right), the one on the left stores a number smaller than the smallest ID of its descendants, and the number on the right, stores a larger number, than the largest ID of its descendants, so to do a query , we would have a search scope, which in terms of efficient than the other methods, see an image that illustrates this:
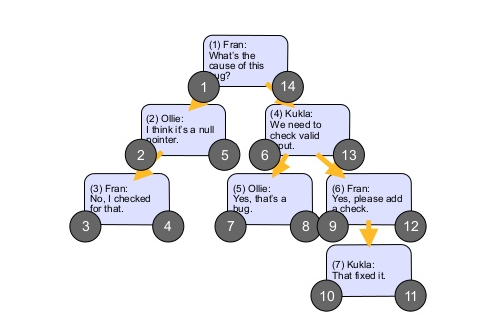
Positive points : much higher Performance, ease of
atravessar.
negative points : much more difficult to implement than the other methods; performance is not so higher in SGDB that does not support recursive queries (example: MySQL)
I recommend asking a question here on StackOverflow about this technique, hence me or another user we can show you how to improve this technique
4. Relationship table
Basically a "many-to-many" table that stores all the connections of a node with its descendants, similar to the enumerated path technique, but a little more flexible and with more performance than such.
P.S. I will improve this answer as soon as possible by citing more examples, but this is a giant subject, and each of the techniques would yield at least one question here in SO
To determine the best structure to represent your tree, ask the following questions:
-
Maximum depth is guaranteed very small ? (i.e. a maximum of 3)
If the answer is Yes , a simpler solution may be the ideal one (more complex solutions "pay off" when the scale of the problem is large). The" adjacency List " (Adjacency List ) - where each node has a foreign key to your father-is a simple and straightforward solution. However, there are authors who consider it a "naive solution" (naïve) - applicable yes in simple cases, but in general to be avoided.
Note that it may be necessary to write more than one query depending on the depth of the node (e.g., one for depth 1, one for 2, one for 3), so the tree requirement is guaranteed to be shallow. Some DBMS support" recursive queries " (eg.:
WITH,START WITHandCONNECT BY) which may simplify the task, but are not portable, which escapes the scope of the question. -
Is the maximum predicted depth small ?
Another simple technique, but without the problems of the list of adjacencies is the" path Enumeration " (Path Enumeration ), where each node has a textual column where the list of
ids is represented from the root to that node. It is simple both to insert/remove / modify nodes and to scroll through them (either the sub-avor, or their direct children), just one operation in the textual field - usually involving prefixes.It is good to note that this table would be denormalized (it is not in the first normal form ) and does not have referential integrity (the column would accept lists with nonexistent
ids), besides what paths can become very long in deep trees. (the space requirement of a node is proportional to its depth) -
A maximum predicted depth is too large ? Are there nodes that are ancestors of most other nodes?
If the answer is No, consider using a closure Table (which @hernandes called a "relationship table", but could also be called a " closure table") - a separate table where each row represents a relationship
ancestral -> descendente(and perhapsprofundidade). This table provides speed of access in exchange for greater storage space. storage, and it is efficient for virtually every type of operation.A disadvantage (if using pure SQL) is the need to keep two tables up to date, and relatively complex (but efficient) queries. And if the depth is too large, the leaf nodes will have a large number of ancestors, each occupying a row at the closure. (the space requirement of a node is also proportional to the depth, but the overhead is greater - one line for each ancestor) a alternative technique may be interesting unless...
-
Is your tree modified frequently? Does your table represent more than one tree? (and is it feasible that two trees will be "merged" at some point?)
If the answer is not, the use of "nested sets" can offer good performance with low space consumption. In it each node defines a range (two numbers: lower/left limit and upper/right limit) and any node whose range is contained (nested) in the range of another node is considered to be "descending". In general, query queries are simple and efficient, and the space requirement is small and fixed for each node (two integers).
However, although the removal of a node is cheap, the insertion or locomotion of a node can be quite expensive, since it is necessary to update all its ancestors, its brothers (from the right traditionally, but a variation would be to choose the side with less brothers) and the brothers of all their ancestors (same side). If the knot is not leaf, so are its descendants. If time is more important than space, it is preferable to adopt the Closure Table in this situation.
Note: If your table represents more than one tree, there is an additional complication: unless each node identifies which tree it belongs to, the sets of one tree could interfere with the sets of the other. This would cause changes in a node would affect even nodes of other trees ! And if Tree merging is possible, the whole set of one of them would at least have to be redone.
Complete examples would be very extensive for this answer, but I will include a comparative table of the techniques mentioned (source: book "SQL Antipatterns" ), and only the code sample requested in the question (i.e. query to cross a sub-tree).
Design Tabelas Consultar Filho C. Sub-Árvore Inserção Remoção I. Referencial
Lista de Adj. 1 Fácil Difícil Fácil Fácil Sim
+Query Recurs. 1 Fácil Fácil Fácil Fácil Sim
Enum. Caminhos 1 Fácil Fácil Fácil Fácil Não
Conj. Aninhados 1 Difícil Fácil Difícil Difícil Não
Closure Table 2 Fácil Fácil Fácil Fácil Sim
-
List of adjacencies (node subtree
4, up to 3 levels):select * from comentarios where id = 4 union select * from comentarios where parent = 4 union select c2.* from comentarios as c1 join comentarios as c2 on c2.parent = c1.id where c1.parent = 4; -
Enumeration of paths (node subtree
1/4/):select * from comentarios as c where c.caminho like '1/4/' || '%';(remembering: search for nodes whose path has the prefix
1/4/) -
Nested sets (node subtree
4):select c2.* from comentarios as c1 join comentarios as c2 on c2.esquerda between c1.esquerda and c1.direita where c1.id = 4;(reminding: searches for nodes whose range -
esquerda, and automaticallydireita- is fully contained in the range of the node) -
Closure Table (node subtree
4):select c.* from comentarios as c join closure as ad on c.id = ad.descendente where ad.ancestral = 4;
I would like to have put as a comment the answer of @ hernandes, however, it was a little extensive, so I put here as an answer.
I am using adjacent list on some systems. One drawback is the work on making things like a breadcumb. It also has a difficulty in determining when a node is disabled and preventing its dependencies from being displayed, or even for enabled ones checking for related and active dependencies (products from a virtual store, for example).
I do not advise any of these techniques (adjacency, nested, etc) when the system is restricted to a small depth of up to 5 knots, for example. If we analyze well, a virtual store will hardly have subcategories with more than 5 levels of depth. Finally, before the choice, one must understand what the business model is.
Online Store? CRM? File system?