Using groupby on pandas dataframe
Good afternoon.
I don't have much skill with Python, I'm having some doubts. Anyone who can help me, since I thank you.
I opened my csv file in python as follows:
import pandas as pd
caminhoArquivo = r'\\Desktop\Base\dias.csv'
baseDados = pd.read_csv(caminhoArquivo,sep=';',decimal=',',encoding='latin-1')
File example:
Index | Nome | Dia
0 | Pedro | 3
1 | Pedro | 3
2 | Pedro | 24
3 | Antonio| 24
4 | Antonio| 24
5 | Antonio| 24
6 | Carlos | 4
7 | Carlos | 4
8 | Carlos | 28
9 | Jose | 1
10 | Jose | 2
11 | Jose | 2
I removed the duplicate data using the command:
colunas = ['Nome','Dia']
diaDuplicado = baseDados.drop_duplicates(subset = colunas)
diaDuplicado = diaDuplicado.reset_index()
So it was:
Index | index | Nome | Dia
0 | 0 | Pedro | 3
1 | 2 | Pedro | 24
2 | 3 | Antonio| 24
3 | 6 | Carlos | 4
4 | 8 | Carlos | 28
5 | 9 | Jose | 1
6 | 10 | Jose | 2
Now my doubt. I needed to group the days by names, to stay this way:
Index | Nome | Dia
0 | Pedro | 3, 24
1 | Antonio| 24
2 | Carlos | 4, 28
3 | Jose | 1, 2
However, the only solution what I found was:
diasgroup = diaDuplicado.groupby(by=['Nome'])['Dia'].apply(list)
But this way it turns the column "name" into index and gets into an "object"format/type.
Index | Dia
Pedro | 3, 24
Antonio| 24
Carlos | 4, 28
Jose | 1, 2
Could you help me?
3 answers
Using the function groupby:
df[['Nome', 'Dia']].groupby('Nome').agg(lambda x: list(set(x))).reset_index()
Out[6]:
Nome Dia
0 Antonio [24]
1 Carlos [4, 28]
2 Jose [1, 2]
3 Pedro [24, 3]
dtype: object
Edited
Rereading the question I saw that the author of the question had achieved what he wanted but said that the result is an object and that the names become clues, or something like that. I was wondering if even if it can "navigate" that object and throw the elements into a list, dictionary or qq other variable, wouldn't it answer? I will keep my original answer, in case the requirement has to be aDataFramebut I will put below the code to iterate in the object that is obtained by converting theDataFrameto list, apandas.core.series.Series, (I will use the code fragment that it uses in the question, to create the object):
# Criando o pandas.core.series.Series
diasgroup = diaDuplicado.groupby(by=['Nome'])['Dia'].apply(list)
# Navegando em diasgroup
for i in diasgroup.items():
print(i)
Saida:
('Antonio', [24])
('Carlos', [4, 28])
('Jose', [1, 2])
('Pedro', [3, 24])
Henceforth it is for the case where result needs to be a DataFrame:
I'm not sure if pandas presents the data exactly the way vc wants in groupby, but vc can convert to an empty multindex dataframe, which presents something like this:
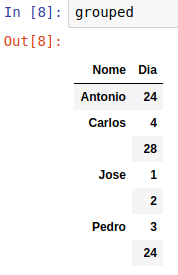
I'm presenting the photo, because when I can only get this output, in a jupyter notebook when I type the name of df, without the function print, with the print function, the result is this:
Empty DataFrame
Columns: []
Index: [(Antonio, 24), (Carlos, 4), (Carlos, 28), (Jose, 1), (Jose, 2),
(Pedro, 3), (Pedro, 24)]
See that qq way to navigate the indexes and extract the information you need.
Let's go to the code:
import io
import pandas as pd
s = '''
Nome,Dia
Pedro,3
Pedro,3
Pedro,24
Antonio,24
Antonio,24
Antonio,24
Carlos,4
Carlos,4
Carlos,28
Jose,1
Jose,2
Jose,2
'''
df = pd.read_csv(io.StringIO(s), parse_dates=True)
df = df.drop_duplicates(subset = ['Nome','Dia'])
grouped = df.groupby(['Nome', 'Dia']).sum()
print(grouped)
Output:
Empty DataFrame
Columns: []
Index: [(Antonio, 24), (Carlos, 4), (Carlos, 28), (Jose, 1), (Jose, 2),
(Pedro, 3), (Pedro, 24)]
See working on repl.it.
The answer involves a few steps.
Creating the already deduplicated DataFrame:
import pandas as pd
diaDuplicado = pd.DataFrame(columns=["Nome", "dia"],
data=[["Pedro", 3],
["Pedro", 24],
["Antonio", 24],
["Carlos", 4],
["Carlos",28],
["Jose", 1],
["Jose", 2]])
A DataFrame:
print(diaDuplicado)
Nome dia
0 Pedro 3
1 Pedro 24
2 Antonio 24
3 Carlos 4
4 Carlos 28
5 Jose 1
6 Jose 2
In sequence, generating tuples in a series. The reason we generate tuples (and not lists here) is that lists are not hashable , which in practice implies that Pandas cannot deduplicate lists:
d = k.groupby(by=['Nome'])['dia'].apply(tuple)
The result is:
Nome
Antonio (24,)
Carlos (4, 28)
Jose (1, 2)
Pedro (3, 24)
Name: dia, dtype: object
Merging the two Dataframes by the correct keys:
p = pd.merge(k, d, left_on="Nome", right_index=True)
print(p)
Nome dia_x dia_y
0 Pedro 3 (3, 24)
1 Pedro 24 (3, 24)
2 Antonio 24 (24,)
3 Carlos 4 (4, 28)
4 Carlos 28 (4, 28)
5 Jose 1 (1, 2)
6 Jose 2 (1, 2)
Now just deduplicate again, considering the columns of interest:
colunas = ['Nome','dia_y']
diaDuplicado = p.drop_duplicates(subset = colunas)
What results in the dataframe:
Nome dia_x dia_y
0 Pedro 3 (3, 24)
2 Antonio 24 (24,)
3 Carlos 4 (4, 28)
5 Jose 1 (1, 2)
Now just convert the column "dia_y" to list and drop the column dia_x and dia_y:
diaDuplicado["DiaLista"] = diaDuplicado["dia_y"].apply(list)
diaLista=diaDuplicado.drop(["dia_x", "dia_y"], axis=1)
What results in the "dialist" DataFrame:
Nome DiaLista
0 Pedro [3, 24]
2 Antonio [24]
3 Carlos [4, 28]
5 Jose [1, 2]