What is overfitting and Underfitting in Machine Learning
What is Overfitting and Underfitting in machine learning ? I am studying a little on the subject and I was curious where this applies.
2 answers
Overfitting and Underfitting in Machine Learning are classifications or concepts in model fit. But then what? What's that?
Speaking of machine learning , there are basically three types of machine learning, which is Reinforcement Learning, supervised and unsupervised . Supervised learning is based on a set of techniques to adjust function parameters so that these functions satisfy some conditions that are given by the values of the labels. When we have these parameters adjusted and we already know which function we are trying to calculate, we say that we have a model.
For this, machine learning algorithms perform model fit (from English, model fit ), which occurs while it is being trained based on the data so that it becomes possible to make predictions with the model (from English, model predict ) as trained using the tags. With this, you can define overfitting and underfitting.
This understanding will guide you to take corrective action. One can determine whether a predictive model is under-adjusting or over-adjusting training data by querying the prediction error in training data and evaluation data. Understanding model fit is important to understanding the root cause of model accuracy unsatisfactory.
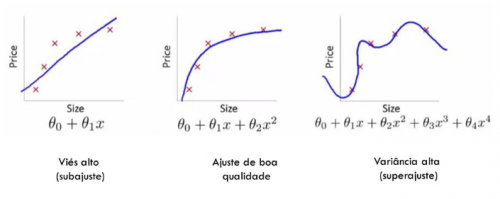
The Model overfitting occurs when the model has adapted very well to the data it is being trained with; however, it does not generalize well to new data. That is, the model "decorated" the training dataset, but did not actually learn what differentiates those data for when it needs to face new tests.
The Model underfitting occurs when the model does not adapt well even to the data with which it was trained.
See in graph as they are represented:
References
Overfitting is a term used in statistics to describe when a statistical model fits very well with the previously observed dataset, but proves ineffective in predicting new results.
It is common for the sample to have deviations caused by measurement errors or random factors. Over-adjustment occurs when the model adjusts to these. An over-adjusted model has high accuracy when tested with its data set, but such a model it is not a good representation of reality and so should be avoided. It is quite common that these models have considerable variance and that their graphs have several small oscillations, so it is expected that representative models are convex.
One tool to work around the over-adjustment problem is regularization, which adds the value of the parameters to the cost function. Such an addition results in the elimination of unimportant parameters and therefore a more convex model, which is expected to be more representative of reality. Through cross-validation, where we test our model against a reserved part of the dataset that was not used in the training of the model in question, it is possible to get an idea of whether the model suffers from over-adjustment or not.
Underfitting, the counterpart of overfitting, happens when a machine learning model is not complex enough to accurately capture the relationships between the features of a dataset and a target variable. An insufficient model results in problematic or erroneous results in new data, or data in which you have not been trained, and often performs poorly, even in training data.
Sources: https://www.datarobot.com/wiki/underfitting / https://pt.wikipedia.org/wiki/Sobreajuste