What is the best way to represent an address?
To model the address in an application and is committed to follow the standard way to represent it in the db (i.e. separate tables to the country, state, city, neighborhood of and so forth - join for all sides)and the user interface (html) and put it in a separate field for each part of the address (the text-box and search or combo box - ). At first I thought it was good that way, and I didn't think much about subject.
However, after asking a question in the UX.SE (relative to our pattern of using "X Street" instead of "X street") the answers led me to question whether it was worth in practice requiring size level of detail in the representation. In addition to the additional complexity when it comes to fetching/updating (as exemplified in this "pyramid"), I don't know how the performance of the system will be when it contains a large number of addresses.
I would like to know, from who already has Experience dealing with a large number of addresses, what practices would be recommended: leave everything normalized, use an open text field, condense some tables into one (e.g. cidade_estado_pais) and leave others separate, etc. Taking into account that:
- few users will enter with many addresses, of other people (if it were each user entering with their own address once and done, it would not justify investing in usability).
- if a part of the address already exists in the bank (e.g. a previously registered street) autocomplete can be used to speed up data entry; this would be more difficult if the address was an open field.
- some data is easier to find and pre-popular (e.g.: complete list of Brazilian cities), others are more difficult or more expensive - it may be better for the user to enter them on demand (but still allowing autocomplete).
- if a field is opened, it is more subject to duplication (e.g. "Av Foo", "Av. Foo", "Avenue Foo"," A. Foo"," Foo"); but duplication is not necessarily a problem...
- it is more difficult to aggregate in a denormalized field(e.g. if I want statistics by state, but I grouped
cidade_estado_paisin one field, I will have problems).
4 answers
In my opinion the best database of addresses in Brazil is the e-DNE that has more than 900 thousand records and, in my opinion, works very fast.
Follow the diagram of their bank.
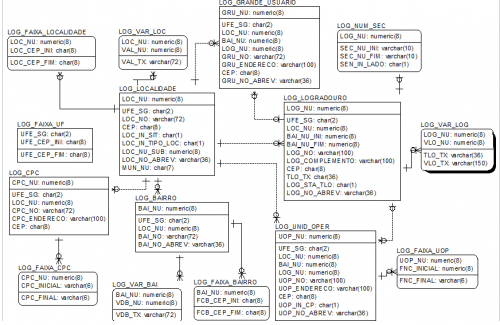
When I needed to use this bank I found it very simple easy and fast, I believe it will serve your purposes and of course this mail bank is very complex because it covers many things but you can reduce it for your purposes.
Here you can download a zip with the bank model and a doc file that explains very straight how it works. So I don't think we need to reinvent the wheel, let's mirror ourselves in the best...
Now in the question duplicate address and duplicate data in general, the best way to solve this is a very intelligent algorithm that will compare the data provided and cross with information to try to unify the information.
I recommend reading this link, and good luck after all is not a simple task, but achieving the expected results is very rewarding.
In our case, the way the data is organized is directly linked to the use of the same to facilitate its completion, collection and analysis, i.e.:
-
If we are going to conduct research or compile statistics on certain information, that information must be separate:
Statistics about the person's location, requires that the field
localidadebe in a column for him alone.Example:
Coimbra -
If the field is not relevant to surveys or statistics, the field may be along with other information:
The case of the streets where the person resides, which may have short or long names, but are not subject to analysis, may be in one column:
Example:
Av. da LiberdadeorAvenida da Liberdadeis equal. It boils down to text that separated into two columns, one for the street type and one for the street name will only generate confusion when filling in and / or collecting that information.
Having everything separate if there is no benefit is unnecessary. Having it all together and then needing to analyze the data separately doesn't make sense either.
What we try to do is find out which data is more common and easier to manage separately. Then we cross this result with the data that we already know will be subject to analysis, taking into account those that may in the future also be subject to analysis.
With the result, we have a good idea of how we should keep all the information.
On the other hand, we also have to consider the use of secondary tables, as is the case with countries. It makes no sense for a user to have to write the name of their country if in the whole world there are X countries and this number is rare to change, it makes perfect sense to have a secondary table with the countries and the user only has to select his own.
Working on a gigantic project, I realized that it is not possible to escape much from this way of treating this paradigm, leaving each table separated by Place, neighborhood, city...etc. Something important is always to keep indexes in all tables and optimize their queries, today we also make a filter, so that the user is more specific in the search if it brings many results, my development team is remodeling the system from scratch starting with the BD, a priori this is the experience that I had, in case we get to this part of the modeling of the bank, and something is modified I will be happy to come in this question and demonstrate to have something more concrete for you, I hope that even if little has contributed...
I would like to know, from those who already have experience dealing with a large number of addresses, what practices would be recommended: leave everything normalized, use an open text field, condense some tables into one (e.g. city_state_pais) and leave others separate, etc.
In the company where I work I am responsible for a service that consolidates addresses from various other systems. Since you mentioned the issue of experience much of what I will talk about here is experience / opnion mine.
" normalize or not?
Normalize. Unless not being what you are doing is extremely simplistic, I recommend normalizing the data. The consistency of the data will not only relieve you of future problems (it is, for example, more difficult to enter an invalid address) but will also prevent a plastering of this data (a possible report or integration with another system that has this normalized data).
" add tables?
I see no need. The only possibility of aggregating tables I see is in the example you cited (city-state-country). If properly modeled an eventual join or search will not generate a significant overhead.
" backyard type?
There are systems that dedicate a column of their own to the type of address (Avenue, Street, Mall, etc.). I don't think it's important to do it unless it really is necessary.
Think, for example, how to extract this user-provided information. Or do you make a select (drop down list ) and forces the user to select a correct log type (which is not very functional/pleasant) or tries to extract this information from the log field (which can be tricky to do correctly or leave the flow stuck).
" How to model after all?
Follows a practical example of the service I mentioned. The actual base I have hundreds of thousands of addresses.
Table Endereco:
-
CEP: table PK. Field with exactly 8 characters. Always without a mask. -
Logradouro: including the yard type and address number. Bairro-
Localidade: City. It has an index. -
UF: field with exactly 2 characters. It is an FK for the table of Federative units. -
Data: date of registration/update of the address.
Table Unidade Federativa
-
Sigla: table PK. Field with exactly 2 characters. State acronym. -
Nome: full name of the state.
" initial loads
Recommend only for Federative unit and city. Federative Unit changes are very rare. city it is already more common to have changes but nothing that is not possible to maintain. Any more localized field, such as neighborhood , already becomes difficult to maintain a load.
Obs.: I mean data that is not entered by users. Given these static maintained by the system itself (often manually by the developers themselves). Therefore the recommendation to do only with city and Federative unit .
" search column? Index!
Remember to create index in the columns you search in them (ex: neighborhood autocomplete).
" each case is a case
The recommendations I leave are for relational database and Brazil addresses. Remember to adapt and put your own knowledge and criticism into modeling your system. After all, each case is a case.